AIGC动态欢迎阅读
原标题:复旦MOSS团队:数据
配比的scalinglaw
关键字:数据,模型,比例,报告,领域文章来源:算法邦
内容字数:5345字内容摘要:
智猩猩与智东西将于4月18-19日在北京共同举办2024中国生成式AI大会,爱诗科技创始人王长虎,启明创投合伙人周志峰,Open-Sora开发团队潞晨科技创始人尤洋,「清华系Sora」生数科技CEO唐家渝,万兴科技副总裁朱伟,优必选研究院执行院长焦继超等40+位嘉宾已确认带来演讲和报告,欢迎报名。这次,复旦MOSS团队带着数据配比scaling laws就来了。题目:Data Mixing Laws: Optimizing Data Mixture by Predicting Language Modeling Performance
地址:https://arxiv.org/abs/2403.16952
代码:https://github.com/yegcjs/mixinglaws
现有关于多样性的研究,通常依赖于启发式或定性策略来调整混合比例,缺乏对模型性能与数据混合比例关系的定量理解。
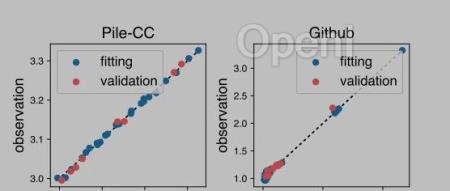
这篇文章旨在探索模型性能与数据混合比例之间的定量可预测性,并提出一种方法来优化数据混合比例,以提升预训练模型的效率和性能。
说白了,就是量化多样性和loss的关系,通过在小规模数据集上拟合这多样性原文链接:复旦MOSS团队:数据配比的scalinglaw
联系作者
文章来源:算法邦
作者微信:allplusai
作者简介:智猩猩矩阵账号之一,连接AI新青年,讲解研究成果,分享系统思考。