AIGC动态欢迎阅读
原标题:上海交大新框架解锁CLIP长文本能力,多模态生成细节拿捏,图像
检索能力显著提升
关键字:文本,图像,腾讯,位置,能力
文章来源:量子位
内容字数:3954字内容摘要:
白交 发自 凹非寺量子位 | 公众号 QbitAICLIP长文本能力被解锁,图像检索任务表现显著提升!
一些关键细节也能被捕捉到。上海交大联合上海AI实验室提出新框架Long-CLIP。
△棕色文本为区分两张图的关键细节Long-CLIP在保持CLIP原始特征空间的基础上,在图像生成等下游任务中即插即用,实现长文本细粒度图像生成——
长文本-图像检索提升20%,短文本-图像检索提升6%。
解锁CLIP长文本能力CLIP对齐了视觉与文本模态,拥有强大的zero-shot泛化能力。因此,CLIP被广泛应用在各种多模态任务中,如图像分类、文本图像检索、图像生成等。
但CLIP的一大弊病是在于长文本能力的缺失。
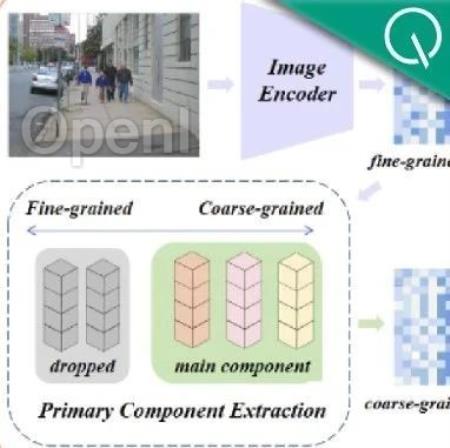
首先,由于采用了绝对位置编码,CLIP的文本输入长度被限制在了77个token。不仅如此,实验发现CLIP真正的有效长度甚至不足20个token,远远不足以表征细粒度信息。
文本端的长文本缺失也限制了视觉端的能力。由于仅包含短文本,CLIP的视觉编码器也只会提取一张图片中最主要的成分,而忽略了各种细节。这对跨模态检索等细粒度任务是十分不利的。
同时,长文本的缺乏也使CLIP采取了类似b原文链接:上海交大新框架解锁CLIP长文本能力,多模态生成细节拿捏,图像检索能力显著提升
联系作者
文章来源:量子位
作者微信:QbitAI
作者简介:追踪人工智能新趋势,关注科技行业新突破




